Systematic review automation methods#
Revues et commentaires de la thèse de Christopher Norman, Systematic review automation methods (2020).
Raw english notes#
What does it mean to automate the reviews? What are the obstacles ? The thesis focuses on diagnosis test accuracy (DTA) reviews.
Background and context#
One of the main characteristics of a Systematic Review (SR) is to be reproductible. 📑NB: if using LLM, we need to pin their version.
Cost and time of SRs: A SR on intervention efficacy takes 67 weeks on average to complete. Based on AHRQ figures, it costs 300, 000 dollars to review 10, 000 references.
The Systematic review process#
Time spent: 26% spent on search and retrieval, 24% on data collection, 23% on writing manuscript, 17% on statistical analysis (Pham et al, 2018).
Some well known tools are: RevMan (required for Cochrane SRs), Rayyan, Covidence, and DistillerSR. Prospero is used to register and avoid duplication of SRs.
📑NB:If some of these tools are easily accessible by API, we might call them with the LLM.
The systematic review process is best described by the Cochrane:
Write protocol (Formulate question, define eligibility criteria (pico), target databases, construct search queries)
Search and screen (run search, deduplicate, screen abstracts, retrieve full text, screen full text, search reference lists)
Write review (extract, homogenize, synthesize, recheck due to length of the SR, meta-analyze, write)
Google scholar indexes virtualy all papers (Gehanno et al., 2013) but is not searchable with a boolean query.
Systematic review automation: screening automation#
The first work focuses on actualizing the O’Mara-Eves et al. (2015) review on automation of SRs.
Evaluation metrics used in previous literature: Recall (ie. sensitivity, ie. TPR), Precision, Specificity (ie. TNR), Accuracy, F measure, ROC (AUC). Worked Saved Over Sampling, percentage of references not needed to screen to retrieve \(100-\alpha\%\) of the included: \(wss@\alpha=\frac{TN+FN}{TP+TN+FP+FN}-\alpha\), abandoned since it fails to discriminate different recalls and have large variance, since it depends on the end of the ranking.
📑Note: Because of usually highly imbalanced data, AUPRC could be more relevant than ROC AUC.
Cost analysis for FP is easy to run (30-60 sec of supplementary workload) but FN is harder to estimate since it might introduced bias in the results of the SRs.
Available datasets:
Cohen et al. (2016): 15 reviews on drug effectiveness. Closest thing to a standard but: a) topic overlap with references included in more than one review leading to information leakage if included in different train sets b) 2,150 references have no abstracts in PubMed c) One reference not indexed in PubMed. The number of articles varies between 300 and 3K per review, totalizing 19K.
CLEF eHealth dataset of 50 DTA reviews, (Kanoulas et al., 2017a, 2018). The test dataset is not blinded for evaluation so it might introduce bias in the reported results. The number of article ranges from 50 to 12K, totalizing 260K articles.
The datasets (CLEF eHealth and Cohen’s) are well-described in Chapter 7 (p.105, ie 127 of the pdf). They describe a high variability of the y/maybe/n ratios, that make the task difficult, especially because of low prevalence.
📑NB: The approach so far has been purely traditional Machine Learning. Notably, there’s no inclusion of the search equation for training, nor the context of the review. This should be considered if using LLMs.
Screening Automation systems#
Focus on screening reduction and screening prioritization.
Consideration of intratopic/intertopic, static/active approaches. 📑NB: Even, if we do not train any model, these remarks are still relevant for model selection and prompt engineering. We have to be carefull when designing evaluation sets to avoid information leakage, especially during prompt design.
They use the following labels: y (included, with abstract and full text), m (ie. maybe, included with abstract but not with full text), n (excluded with abstract). They conclude that distinguishing m from n can be usefull in certain cases where there are few y labels. They recommend to keep the three labels because y/m can be use as positive signal, but N/M together are crucial for evaluation.
Main observations for the CLEF 2017 participation:
No need for full text selection, except if very few y labels.
Logistic regression on top of n-grams is performing as well as RF or SVM
Logistic regression with SGD on KL divergence (logloss) is outperforming classic logistic regression optimizer when there are few Y labels (on CLEF, but not on Cohen’s).
relevance feedback (I understood active learning) is only confusing the system on most of the topics.
Large variability of results is observed with SD up to 0.139 of AUC with 10 repetitions of each experiment.
Their best system is Logistic regression with SGD and no relevance feedback on bag-of-n-grams (n ≤ 3) over words in the titles and abstracts followed by tf-idf and concatenated with paper metadata (keywords, journals, publication type). It yields a workload reduction of 64%.
Main observations for the CLEF 2018 participation:
Update of the 2017 dataset: 50 previous DTA reviews for training, and 30 new DTA reviews for testing.
Featurization; >500K sparse features for the offline (referred as static) model, 2K for the online (relevance feedback).
stacking offline linear regressor and active learning regressor.
Achieve 82.4% workload reduction with 5% recall loss (95M relevant articles retrieved)
Logistic regression outperforms SVM, LSTM, CNN RF.
The combination of intertopic offline model and intratopic online model is the best with saturation at 4 to 6 articles shown (cf. p.138).
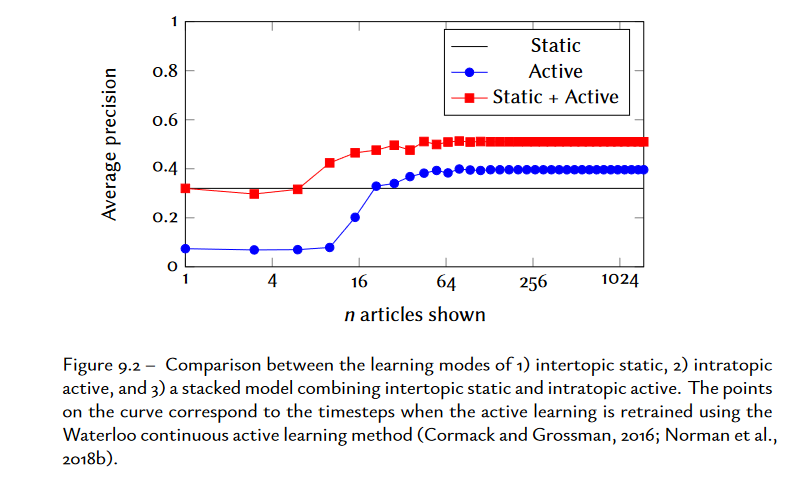
NB: the stacking is an awful combination of different scores and datasets characteristics blended into a single layer NN. To avoid absolutely.
The impact of screening automation#
How to define the sameness of two reviews?
Inappropriateness of commonly used information retrieval measures such as : F1, AUROC, (discounted) cumulative gain (DCG), reciprocical rank, …
Asymetry of costs in SRs between recall (strongly favored) and specificity (weakly favored).
The metrics should give some gaurantee that screening reduction does not influence substantially the results or conclusions of the SRs.
NB: Very interesting idea, that the automation should take into account the effect of adding/deleting a study on the results of the SR. If forgetting a study shifts the effect, there is some problem.
Prospective evaluation: Evaluate the effort-recall with ranking assistant for screening#
Method: LR on 5-grams, followed by tf-idf
Results: decreased by 75% (62.5 hours) the number of articles to screen with a recall of 98% on average.
NB: IMHO, this effort-recall curve is intuitive and aligned with the trade-off of time/recall for SR. NB: No measurement of variability in this article.
When is it safe to stop screening?#
Measure the impact on meta-analysis results of SRs. The point of view here is that recall is less important than estimating accurately a numerical quantity: in the case of Diagniosis Test Accuracy (DTA) reviews, the recall and specificity of the test. To have a scalar as a target quantity, they take the L2 loss of recall and specificity.
Datasets :
LIMSI-COCHRANE dataset 1,939 meta-analyses from 63 systematic reviews of diagnostic test accuracy: structured dataset with the 2x2 extracted contengency tables.
Clef dataset: references for 80 SRs of diagnostic test accuracy from the Cochrane Library. They combine both datasets yielding an intresection of 48 SRs and 1,354 meta-analyses of diagnostic tests.
Many metrics discussed: either retrospective (you need to know how many articles were relevant) or prospective (you don’t know how many articles are relevant). A metric put forward is the displacement of the estimate induced by adding a new article in the meta-analysis.
The 95% recall criterion is a gold standard for review automation but is not necessary for low impact on meta-analysis results.
Conclusion: Screening priorization coupled with stopping critieria in DTA reviews is intersting: reduction of the workload by 95% with 70% recall and 1.3% estimation error on the meta-analysis results. The estimates of meta-analyses converge faster and with fewer variability using screening prioritization than without.
Limit, the vast majorities of the meta-analysis are under-powered: meaning that they have a higher variability than the targeted 2% estimation error of their value. Most of the final estimates (full review process) have high displacement (more than 8%) after the inclusion of the last relevant study.
Important take-away : A reliable meta-analysis requires identifying a sufficient number of studies, but how large a fraction of relevant studies is identified is less important.
NB: interesting ideas of starting the meta-analyses with a priorization (so initial results with confidently few bias) then pursuing them NB: I am bit uncomfortable with the idea of having a “true estimate” of the meta-analysis, which I am not sure what it means. The estimate of the meta-analysis is an ongoing effort to estimate the diagnosis test accuracy in more or less homogenous experimental conditions.
Data extraction and syntesis#
Data extraction and synthesis in DTA SRs#
Existing Datasets (not specific to DTA) :
PIBOSO corpus (Kim et al., 2011)
PICO annotations (Kiritchenko et al., 2010)
They create one such dataset for DTA with all Cohrane Library SRs on DTA. They extracted data from 63 SRs (minus 4 where xml files were available). They used automatic extraction methods which was highly performant, errors coming only from the OCR part and being flagged for inspection. They double annotated one random SR, with 100% inter-annotator agreement. FOr the rest, they only used a single annotator check and post-edite the extracted data tables.
NB: All the technical advices for this manual annotation is out of date. Now, we would do this with ChatGPT4.
Automated data extraction for systematic reviews of diagnostic accuracy#
TODO:
Comment automatiser la revue systématique de littérature#
En se focalisant sur les revues de tests de diagnostic, C. Norman interroge quelles étapes d’une revue systématique sont automatisables et comment établir que l’automatisation a produit des conclusions similaires à une revue manuelle.
La première étape étudiée est celle du screening, plus précisément la priorisation des articles. Les deux datasets utilisés sont décrits avec détails au chapitre 7, table 7.1:
Cohen dataset, (Cohen et al., 2006) incluant 15 revues sur l’efficacité des médicaments. Ce dataset contien 19 000 articles (entre 300 et 3 000 par revue).
CLEF eHealth dataset, (Kanoulas et al., 2017a, 2018): 80 revues sur l’efficacité des tests diagnostiques. Ce dataset contient dans sa version de 2017 (soit 50 revues), 260 000 articles (entre 50 et 12 000 par revue).
Les principales métriques pour le screening priorisé sont le rappel et le work saved over sampling (\(WSS@\alpha\)). Cette métrique correspond au pourcentage de références que l’on peut éviter de screener afin d’obtenir un rappel de \(100-\alpha\%\) comparé à sampler aléoiterment \(100-\alpha\%\) des références (cf. l’illustration de WSS ci-dessous). C’est la quantité de travail évitée par le ranking pour un niveau donnée de rappel. Il est important d’avoir une métrique qui reflète l’utilité d’une revue systèmatique: attribuer une faible importance à un faux positif (ajout d’une minute de travail), mais un fort poids aux faux négatifs, mettant en péril les conclusions de la revue. Les métriques classiques d’extraction d’information ne présente pas cette asymétrie. La thèse utilise également la courbe effort-rappel évaluant le trade-off entre le nombre de références à consulter et le nombre de références pertinentes non incluses.
📑NB: Il me semble que la courbe effort-rappel est une mesure plus complète à partir de laquelle on peut retrouver la métrique \(WSS@\alpha\).
Illustration de Worked Saved Over Sampling: La courbe dessinée est la courbe effort-rappel (SWIFT-Review, Howard et al., 2016)
Le screening priorisé est définie comme une tâche de classification à trois labels : y, inclus à partir de l’abstract et du full text; m, inclus à partir l’abstract mais rejeté avec le full text; n rejeté dès l’abstract. Cette séparation utilise la classe m comme weak labelling pendant l’entraînement. Cependant l’évaluation finale se fait sur deux labels y vs m ou n.
Deux premières études sur CLEF 2017 et CLEF 2018 aboutissent aux conclusions suivantes :
L’avantage de faire l’apprentissage sur le full text n’apparaît que pour les revues avec très peu de labels positifs y.
Les gains de temps sont de plus de \(75\%\) de références évitées pour un rappel de 0.95: \(WSS@95=0.824\) et \(WSS@100=0.779\) avec le meilleur système et un active learning sur CLEF 2018.
Le meilleur système est une régression logistique avec logloss appliqué à des bag-of-n-grams \((n<=3)\).
L’active learning apporte une augmentation de performance intéressante lorsqu’il est ajouté à un pré-entraînement inter-topic (dès une dizaine de références pour une nouvelle revue).
Pour la régression linéaire utiliser une optimisation logloss est mieux que l’optimisateur usuel liblinear.
📑 Ce dernier résultat est sûrement dû à ce que la logloss soit une proper scoring rule; elle optimise les probabilités (utilisée pour la priorisation) et non la classification. Utiliser le brier score doit revenir au même.
Pour utiliser les métriques de recall ou de WSS, il faut qu’une revue soit terminée. La suite des travaux étudient des métriques prospectives, applicables à des revues non terminées. Quand est-il possible d’arrêter de revoir de nouvelles références sans affecter significativement les résultats d’une revue ? Cette question nécessite de définir ce qu’est une déviation acceptable par rapport aux conclusions d’une revue manuelle. L’évaluation quantitative est faite en mesurant l’écart par rapport aux résultat d’une méta-analyse. (L2 norme du rappel et de la précision d’un test). Pour cela, les auteurs crééent un jeu de données de méta-analyses de DTA résultant de l’intersection du CLEF eHealth dataset et du LIMSI-Cochrane dataset. Ce dernier comporte les tables e contingences (TP, FP, TN, FN) de 1,939 méta-analyses extraites de 63 revues systématiques.
Parmi les métriques prospectives étudiées, le displacement permet de reproduire les résultats d’une revue manuelle avec ordre des références aléatoires. Le discplacement mesure l’écart L2 du couple (rappel, précision) à chaque nouvelle référence pertinente incluse dans la méta-analyse. Un critère d’arrêt avec un seuil de 0.02 de displacement donne lieu à une réduction du temps de \(95.6\%\), un rappel de \(50%\) et un erreur d’estimation de \(2.4 points de sensibilité\) et de \(1.0 points de spécificité\). Des critères plus strictes de displacement permettent de se rapprocher de l’estimation de la revue complète. Les auteurs notent que la plupart des méta-analyses ont une erreur standard à \(>=2\%\). Ainsi, le screening priorisé introduit moins de bruit que les modèles de méta-analyse. Ce bruit d’estimation est causé par un nombre de références incluses souvent trop faible.
📑 Cette approche de l’automatisation de la revue de littérature me semble particulièrement intéressante car elle interroge l’impact de l’automatisation sur les conclusions. En revanche, elle implique d’automatiser également l’extraction d’information. De plus, elle laisse de côté la qualité individuelle de chaque étude (GRADE), un composant important lors d’une revue portant sur les interventions en santé et difficilement automatisable.
La dernière partie de la thèse décrit l’extraction automatique d’information pour les revues systématiques. Une étude décrit la construction du Limisi-Cochrane dataset. J’en retiens que les outils pré-LLM sont très performants avec une faible intervention humaine pour correction. Une seconde étude développe un système d’extraction du diagnostic, du test et de la référence. Ils montrent que Biobert ou une LR font aussi bien que des annotateurs humains pour cette tâche.