Quelles évaluations de l’usage des LLMs ?#
A l’occasion d’une présentation à la HAS, je termine deux journées de veille sur l’usage des LLMs (génératifs) dans des contextes professionnels ou scientifiques.
Les expérimentations les plus rigoureuses que j’ai pu trouvées sont celles dans des contextes professionnels (consulting, support client) avec des designs causaux crédibles pour évaluer des outils d’assistance. Ces rares études montrent une hétérogénéité de l’effet en fonction du type de tâche effectuée et des effets plus importants pour les travailleurs les moins compétents.
Pour l’aide à la revue de littérature, je n’ai pas trouvé (mais ai moins spécifiquement cherché) de preuves d’efficacités. Il est possible que cela soit lié à la difficulté de mesurer l’efficacité d’un outil dans ce contexte: qu’appelle-t-on une “bonne” revue ?
J’ai également listé ici quelques études pour le cas d’usage de l’assistance à la programmation informatique: un usage pour lequel il semble avoir un consensus sur l’utilité bien que peu d’études d’évaluation indépendantes existent.
Compétences scolaires#
Plusieurs études déclarent des gains d’efficacité dans un contexte scolaire en utilisant des examens standardisés comme benchmark ou en expérimentant avec des étudiants.
Sur des tests de médecine: Performance of ChatGPT on USMLE, 2023,
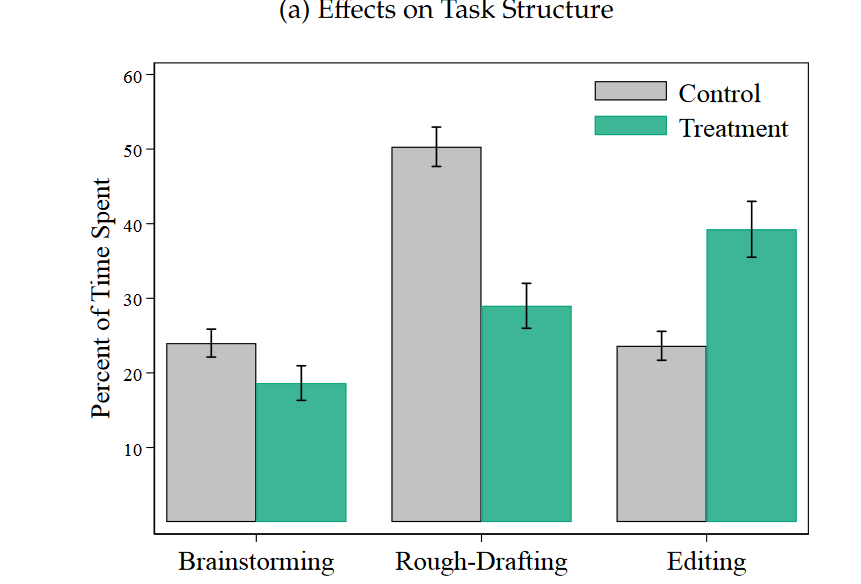
Noy, S., & Zhang, W. (2023). Experimental evidence on the productivity effects of generative artificial intelligence. Available at SSRN 4375283. : Randomisation de 440 élèves de collège montrant une augmentation de la rapidité d’exécution des tâches de 0.8 SD et de la qualité par 0.4 SD (la qualité est notée par des évaluateurs aveugles et payés à noter correctement). Cela dépend grandement du type de tâche effectuée comme le montre la figure suivante :
Un point d’attention à avoir est la grande quantité d’articles d’opinions étudiant cette question de l’utilité des LLMs, comme par exemple cette revue systématique sur l’utilité en santé : ChatGPT Utility in Healthcare Education, Research, and Practice: Systematic Review on the Promising Perspectives and Valid Concerns: Sur les 60 articles retenus, six seulement sont des articles de recherche, les autres sont des editorials, des opinions ou des preprints. La plupart des évaluations sont qualitatives et donc à haut risque de biais. L’article de (Marchandot et al., 2023) est une parfaite illustration de la qualité douteuse du support pour ces revues. Cet article suggère de nouvelle données en faveur de l’utilisation de ChatGPT, alors qu’en réalité, c’est un article d’opinion écrit lui même avec ChatGPT est extrêmement fallacieux. A mon sens, cet article ne fait qu’illustrer la problématique de surpublication.
Assistance pour des tâches professionnelles en condition réelle#
Il ressort sur plusieurs études (scolaire ou professionnel) une augmentation de la productivité, notamment pour les tâches créatives, une plus grande satisfaction des employés et une diminution des inégalités de compétences : Les travailleurs bénéficiant le plus de l’outil sont ceux avec le moins de compétences. Néanmoins, ce genre d’études est encore rare.
Dell’Acqua, et al. (2023). Navigating the jagged technological frontier Harvard Business School Technology & Operations Mgt. Unit Working Paper, (24-013).: Etude randomisée sur 758 consultants évaluant 18 tâches de consulting. En moyenne les consultants utilisant un assistant LLM sont 12% plus efficaces (nombre de tâches effectuées) et 25% plus rapides. Pour certaines tâches (plus créatives), les résultats sont de meilleurs qualité (40% mieux notés ?en double aveugle?). On constate une réduction des inégalités de résultats avec les consultants les moins bons à la baseline, bénéficiant plus de l’outil d’IA que les meilleurs. Mais pour d’autres tâches (plus qualitatives), les résultats sont moins bon de de 19% (capacité à apporter une solution correcte).
Brynjolfsson, E., Li, D., & Raymond, L. R. (2023). Generative AI at work (No. w31161). National Bureau of Economic Research.: Dans un contexte professionnel de support client, ils déploient progressivement un assistant (GPT finetuned sur les interactions utilisateurs) pour 5,000 agents qui produit des suggestions lors d’une interaction client-utilisateur et un lien vers la documentation technique pertinente pour le problème en cours. Le design de l’étude est un diff-in-diff. Les résultats montrent une augmentation de la productivité de 14% (nombre de tâches résolues par heure). D’autres effets positifs sont des clients plus satisfaits, une diminution des demandes au manager et une meilleure rétention des employés.
Revue de la littérature#
Une excellente ressource pour commencer est la présentation d’Aline Bouchard, prof à l’école des Chartes de février 2024.
Dans le contexte de l’évaluation des risques pour des substances chimiques, l’organisme fédéral allemand d’évaluation des risques sanitaires (équivalent ANSES) a publié une étude (financé par le European Food and Safety Administration) sur l’utilisation des outils d’IA pour assister à l’évaluation des risques Exploring the use of Artificial Intelligence (AI) for extracting and integrating data obtained through New Approach Methodologies (NAMs) for chemical risk assessment, Blümmel et al., 2024 : Ils ont testés plusieurs outils d’aide à l’automatisation (Grobid, Gephi, ChatGPT, ) sur six cas d’usages concrets.
L’équipe ML de l’institut de santé publique norvégien a travaillé sur des outils de ML traditionnels: Implementation of machine learning in evidence syntheses in the Cluster for Reviews and Health Technology. Ils insistent sur les gains possibles lors du process de screening.
Capacité à assister une démarche scientifique à partir de grilles d’analyse précises (STROBE) et de rédiger une réponse : A step‑by‑step researcher’s guide to the use of an AI‑based transformer in epidemiology, Sanmarchi et al., 2023. Le papier adopte une démarche intéressante en partant de l’hypothèse que la formulation de la question de recherche est une activité purement humaine guidée par la curiosité (une capacité peu évoquée pour les LLM). Ils concluent avec une évaluation qualitative par des annotateurs humains en insistant sur la nécessité pour l’utilisateur du LLM d’avoir un esprit critique et de bien connaître le sujet.
Assistance au développement de code informatique#
Github a largement marqueté l’efficacité de son modèle de langue pour assister la rédaction du code informatique: De nombreux programmeurs. Un preprint de 2023 de github tend à confirmer ces gains de productivité. Cependant, peu d’études externes sont disponibles évaluant l’étude en pratique courante de programmation. La plupart se focalise sur . L’étude qualitative se basant sur la Grounding Theory de Barke et al., 2023 permet de mieux comprendre comment les programmeurs se servent du LLMs, soulignant l’inadaptation des études d’évaluation existantes focalisées sur la solution à des problèmes spécifiques de code et non à l’assistance au quotidien sur une base de code (la majorité du temps passé en programmation). Un blog post récent listes plusieurs études évaluant la qualité du code informatique produit par IA. Il développe l’étude fermée de gitclear sur 150 millions de ligne de codes entre 2020 et 2023, montrant que la fréquence d’éditions des mêmes lignes de codes est plus fréquentes lorsque les assistants au codage sont utilisés.
Considération de transparence et d’éthique#
Le journal Nature a publié deux nouveaux principes éditoriaux relatifs aux LLM :
Aucun LLM ne peut être crédité comme auteur car l’attribution d’un article renvoie à la responsabilité de l’auteur vis-à-vis de la qualité du travail effectué. Or une IA n’a pas de responsabilité.
Les auteurs utilisant un LLM doivent documenter l’usage qu’ils en font dans la section “Aknowledgements” de leur article.